

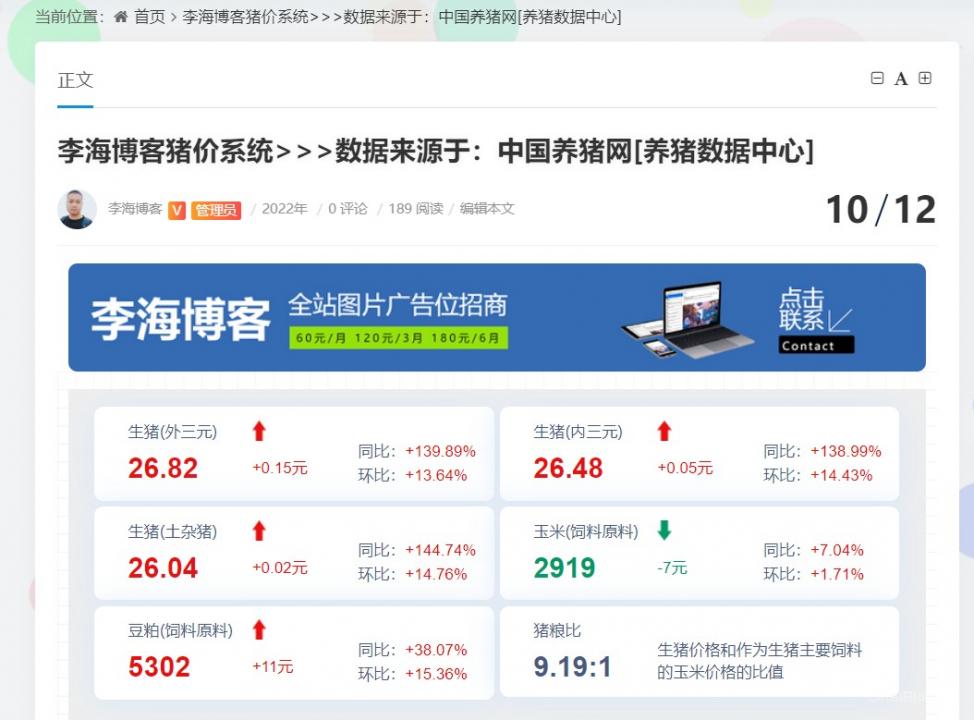
先说一下写这篇文章的缘由,一直想学习从网页上爬取数据为我所用,正好最近想把中国养猪网【养猪数据中心】的数据采集下来放到自己网站做一个“猪价系统”页面,但是不仅仅是把数据爬下来,而且要能实现随源网站数据动态更新。
由于自己对PHP只懂个皮毛,也没学习过其它编程语言,所以对于一直比较感兴趣的“爬虫”也只能从PHP入手,像什么Python爬虫、java爬虫就想都不敢想了。
于是乎到百度上搜索“PHP爬虫”的相关文章,然并卵,并没有一篇能够解决我的痛点。于是乎到B站上去搜“php爬取网页数据”的相关视频,功夫不负有心人,终于找到一个视频是将PHP爬虫的,而且用真实案例讲解,通俗易懂,看完后跟着视频实操真的爬下来了中国养猪网的猪价数据。
李海博客将视频分享给大家,感兴趣的朋友可以去看看:
除了B站视频外,还参考了简书的一篇文章:https://www.jianshu.com/p/c925bb074358,如果B站视频中的代码不可用,可以参考简书文章中的代码:
1.流程
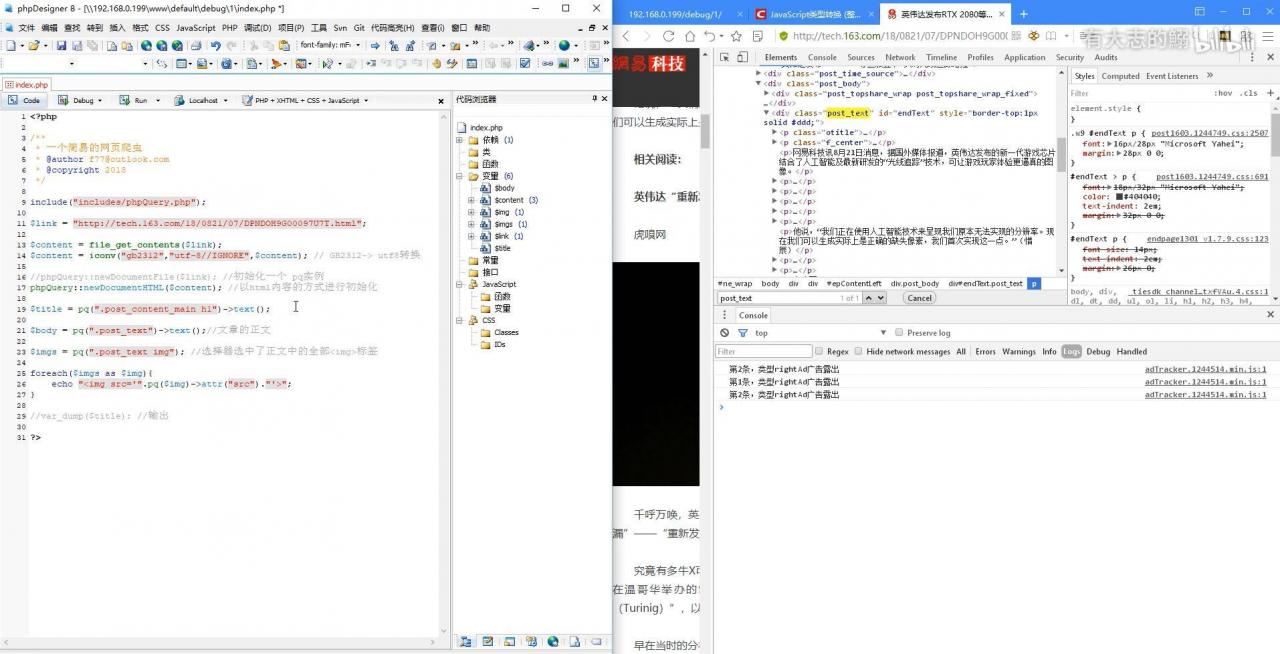
抓取数据的主要流程为先引入phpQuery,接着装载文档,最后通过phpQuery内置的pq函数筛选出我们需要的内容。
header("Content-Type:text/html;charset=gbk;");
require("phpQuery/phpQuery.php"); //引入phpQuery
$url = "http://www.w3school.com.cn/";
phpQuery::newDocumentFile($url); //装载文档
echo pq("h1")->html(); //w3school 在线教程
2.装载文档有很多,这里简单说两种
第一种:
$url = "http://www.w3school.com.cn/";
phpQuery::newDocumentFile($url)
根据目标的url地址,从文件(URL)转载。
第二种:
$url = "http://www.w3school.com.cn/";
$filePath = file_get_contents($url);
phpQuery::newDocumentHTML($filePath);
先用file_get_contents获取网页源代码,然后从标签(字符串)装载文档。
3.pq函数
在装载文档后,我们就获取到一个phpQuery对象,就可以通过pq函数来操作这个phpQuery对象,我们可以和jQuery选择器一样使用pq函数
例如:
pq("#box")->html();
pq(".box:eq(2)")->html();
pq("input[type='text']")->val();
pq(".box")->find("#con")->html();
大家可以依照jQuery的选择器自行尝试。
PHP爬虫依赖于phpQuery,phpQuery是一个基于PHP的服务端开源项目,旨在让PHP开发人员轻松获取网页数据,并进行处理,比如获取某天的天气状况。另外,phpQuery遵序jQuery的思想,可以用jQuery中的选择器来对需要内容进行筛选。
phpQuery下载地址:
Gitee:https://gitee.com/guofu/phpquery
GitHub:https://github.com/TobiaszCudnik/phpquery
从Gitee和GitHub下载的phpQuery,只取用phpQuery文件即可。
由于自己还处在学习和摸索阶段,下一步计划通过学习爬取完整的猪价数据,建立一个自己的猪价系统页面:https://www.lihaiblog.cn/pigprice/








发表评论