

李海博客给大家推荐一个免费的开源无代码网页数据提取平台,它允许用户在几分钟内通过无代码机器人将网站转换为API和电子表格。Maxun 使得训练一个机器人进行网页数据抓取变得非常简单,用户可以在2分钟内完成训练。
Github地址:https://github.com/getmaxun/maxun
主要功能
• 快速训练机器人:用户可以在2分钟内训练一个机器人自动进行网页数据抓取。
• 无需编码:无需编写代码,用户只需通过点击和选择即可收集数据。
• 自托管和云服务:支持自托管和云服务,用户可以根据自己的需求选择。
软件特点
• 无代码数据提取
• 处理分页和滚动
• 按特定时间表运行机器人
• 将网站转换为API
• 将网站转换为电子表格
• 适应网站布局变化(即将推出)
• 支持登录后的数据提取,包括双因素认证支持(即将推出)
• 集成(目前支持Google Sheets)
机器人能力
• 无代码数据提取:无需编写代码,轻松收集网页数据。
• 处理分页和滚动:轻松处理无限滚动、分页和JavaScript密集型网站。
• 解决验证码和自动轮换代理:解决验证码问题,并维护一个大型代理池,以实现精确到国家、州或邮政编码级别的目标数据提取。
• 适应网站布局变化:自动修复所有数据选择器,即使网站布局变化,机器人也能持续提取数据。
• 按计划或通过API运行:可以安排机器人在特定时间或定期运行,也可以通过API运行机器人,集成到现有系统中。
• 登录后提取数据,支持双因素认证:即使需要2FA或MFA,也可以登录并从登录后提取数据。
数据转换
• 将网站转换为API:将任何网站转换为强大的API,实时访问数据并自动化工作流程。
• 将网站转换为实时数据库:通过将数据添加到Google Sheets和Airtable,将任何网站转换为实时数据库。(更多集成即将推出)
本地设置
Docker Compose:
1. 克隆项目:git clone https://github.com/getmaxun/maxun
2. 启动容器:docker-compose up -d --build
无Docker:
1. 确保系统已安装Node.js、PostgreSQL、MinIO和Redis。
2. 克隆项目:git clone https://github.com/getmaxun/maxun
3. 进入项目根目录:cd maxun
4. 安装依赖:npm install
5. 进入maxun-core目录安装依赖:cd maxun-core 和 npm install
6. 启动前端和后端:npm run start
7. 访问前端:http://localhost:5173/,后端:http://localhost:8080/
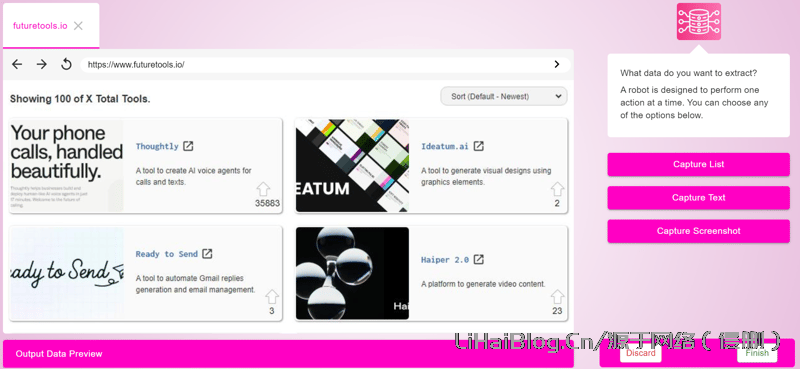
工作原理
Maxun允许创建自定义机器人,模拟用户行为并提取数据。机器人可以执行以下操作:
1. Capture List:从网站提取结构化和批量项目,例如从亚马逊抓取产品。
2. Capture Text:从网站提取单个文本内容。
3. Capture Screenshot:获取网站的全页或可见部分截图。








发表评论